










 5 / 54
5 / 54

W H I T E P A P E R
www.persistent.com
© 2017 Persistent Systems Ltd. All rights reserved.
5
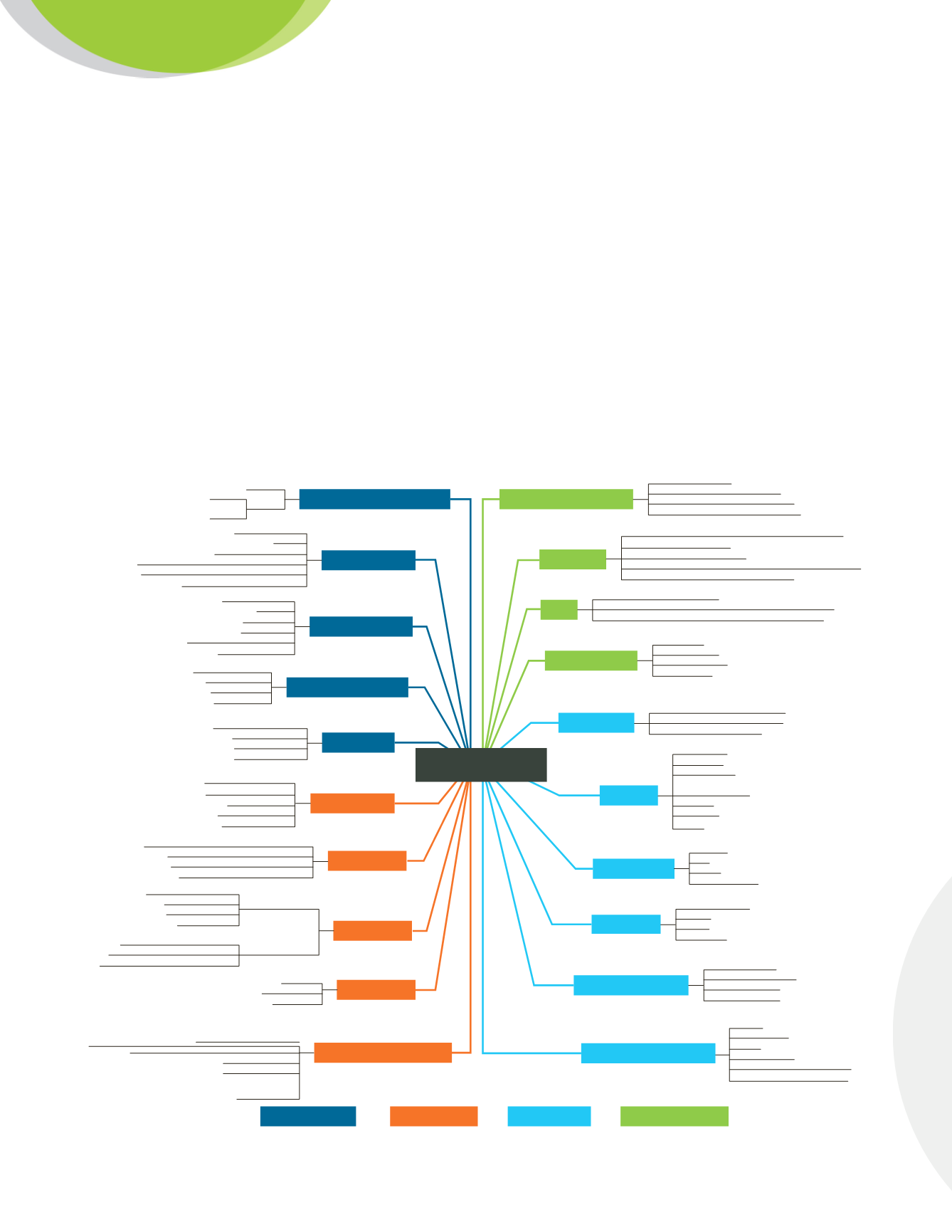
Please refer to the figure below where groupings are color-coded for easier understanding. These factors should
be self-explanatory (except for performance and scalability, on which we comment below); they are presented as
a collection of “requirement dimensions”, each with possible value points, or members. Sections 4 and 5 below
will be constantly referring to these dimensions (which will be written in
bold
when referring explicitly to them)
and their member values.
Customer requirements should be accurately expressed using members from these dimensions. Some
dimensions take unique members to describe requirements: for instance, the
Data Volume
dimension, a single
value such as “small: less than 1 TB”, or “medium: 1 TB – 20 TB”, etc., is generally assumed to be chosen
(although not absolutely required if there are several datasets on which a separate analysis is required). On the
other hand, some dimensions generally take several values: an example is
Analytic Workloads
, which may take
“Reports”, “Data Discovery” and “Dashboards” for a given customer.
Knowledge about queries
Internal technical skills
User skills
Cost
Pricing Models
Compliance
Security
Performance
Type of queries
Analytic Workload
Query response times
User scales
Factors to consider for
Cloud Analytics
Data volumes
Data velocity
Data variety
Known
UnknownDataset Exploration
Profiling
Statistical model building
Filtering, joining, simple aggregations, browsing
OLAP style complex multidimensional analysis
Point queries: data access via APIs
Canned
Ad-hoc
Authorization
Authentication
Network security
Virtual private clouds
(IaaS through virtual network connections)
Encryption
Tokenization
Auditing
Data transforms
(Filter, Join, Union, Sort, Aggregation, case, pivot/unpivot...)
Data cleansing and matching
History preserving (slowly changing dimensions)
Change data capture
Real time processing
Batch processing
Backups
High availability
Failover
Disaster recovery
Software updates/patches/plugins
Optimize cluster for performance
Dataset discovery
Reporting
Dashboarding
Operational BI
Data mining/machine learning
Analytic applications
Fast: 200 ms - 3 s
Very fast 10 - 200 ms
Average: 3 - 10 s
Non-interactive
Right staffed, available
Right staffed, staff partially available
Some existing skills, some staffing needs
No development skills, large staffing needs
Pay per resources
Pay as you go
Pay per subscription
Pay for features
High
Very high
Medium
Average and below
Scalability
Consistency model
Resource Management
Scale out
Elastic computation
Scale up
No scalability
Single record consistency
ACID transactions
Eventual consistency
No writes (read only)
High: 1.000 - 50,000
Very High: beyond 50.000
Medium: 100 - 1.000
Small: less than 100
Type of data
Data integration/quality
Very high: Beyond 500.000 records per second
High: 100.000 - 500.000 records/second
Large: 10.000 - 100.000 records/second
High: 1.000 - 10.000
Small: less than 1.000 records/second
Very high: beyond 10.000
Number of sources
Stability of sources
Medium: 100 - 1.000
Small: below 100
Very stable (no changes in years)
Stable (changes at least once a year)
Frequently changing (at least monthly)
Structured
Semi-structured
Unstructured
High (associated with private cloud)
Medium (associated with public cloud + IaaS-level data management)
Low (associated with public cloud + PaaS-level data management)
Large: 20 - 100 Tb
High, 100 Tb - 1 petabyte
Very high, petabyte level
Medium: 1 TB - 20 TB
Small: less than 1 Tb
Store data in a public cloud that
meets security and regulatory policies
Store sensitive data in a private cloud
Store sensitive data on premise
Traditional BI developer - SQL level
Data scientist (mining models, machine learning, programming)
Data engineer (scripting, SQL)
Analyst - Excel level: expressions for filtering, grouping, calculations
End user(read report/dashboard, use application)
Query Factors
Data Factors
NFR Factors
Business Factors
Performance
is a complex, derived requirement that can be viewed as a function of query and data requirements.
It generally refers to sustained query response time during a time interval, on a well-specified workload under
control where type of query mix, user scales and data volumes are precisely defined. The same can be said
about
scalability
, a related concept which corresponds to the ability to overcome performance limits by adding
resources, so cost is involved.